



.")

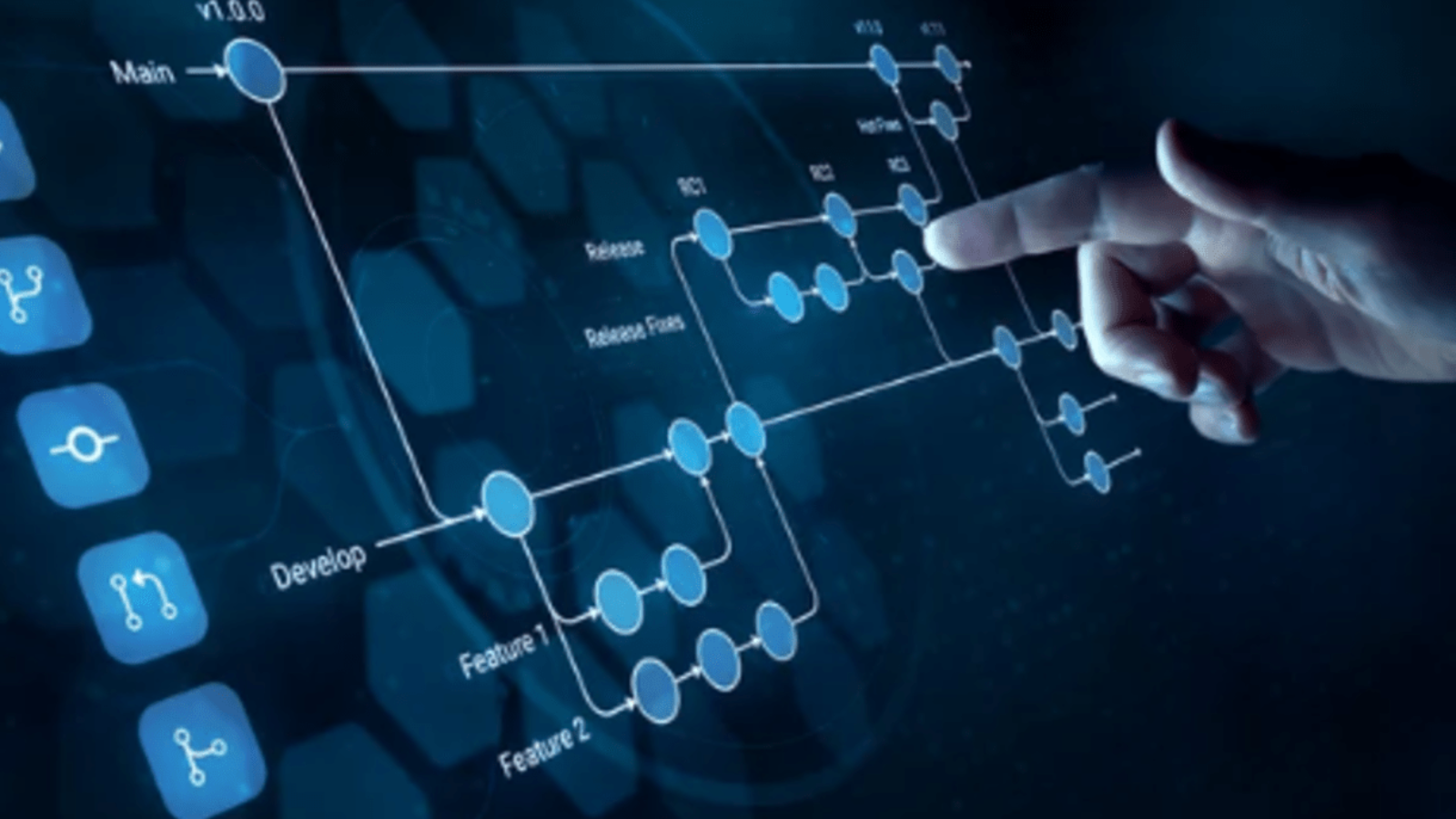
In today’s fast-paced world of software development, managing code effectively has become more important than ever. As projects grow larger and more complex, keeping track of changes manually becomes almost impossible. Developers need a reliable system to store their code, track modifications, and collaborate with teammates seamlessly. This is where version control systems, or VCS, come into play. Version control allows you to record every change made to your files, creating a history that you can revisit at any time.
Among the many tools available, Git has emerged as the most popular and widely adopted system. Git is a distributed version control system, meaning every developer has a complete copy of the repository, including its history. This structure makes Git fast, secure, and ideal for collaboration. Using Git, developers can experiment with new features in isolated branches without affecting the main codebase. If something goes wrong, it is easy to revert changes or roll back to a previous state. Git also makes it simple to work in teams, as multiple developers can work on the same project simultaneously without overwriting each other’s work.
Traditional file management methods often lead to confusion, lost changes, and wasted time. Git solves these problems by providing a clear and structured workflow. Every modification is tracked as a commit, which acts like a snapshot of your project at a specific point in time. These commits can be organized into branches, allowing developers to work on features, bug fixes, or experiments independently. When the work is ready, branches can be merged back into the main project seamlessly.
Git also integrates with remote platforms like GitHub, GitLab, and Bitbucket, which make sharing code and collaborating on projects easier than ever. These platforms allow developers to push their changes, review code through pull requests, and maintain a single source of truth for the project. Moreover, Git encourages good development practices, such as writing meaningful commit messages and committing frequently, which improves project maintainability.
For beginners, understanding Git might seem intimidating at first due to its commands and workflows. However, learning Git step by step opens up a powerful set of tools that make coding, collaboration, and project management much more efficient. By mastering the basics of Git, developers can work with confidence, knowing that their work is safe, tracked, and recoverable. Git is not just a tool; it’s a mindset for organized and collaborative development.
Whether you are working on a small personal project or contributing to a large team, Git provides the structure and flexibility needed to manage code effectively. It allows developers to experiment, fail, learn, and grow without fear of losing progress. In addition, using Git promotes transparency and accountability in software projects, as every change is recorded and attributed to its author.
Over time, the version history becomes a valuable resource for understanding the evolution of a project, debugging issues, and reviewing contributions. Learning Git early in your development journey sets a solid foundation for modern development practices and prepares you for professional collaboration.
In this blog, we will explore the fundamentals of Git, introduce key concepts like commits, branches, merges, and remotes, and provide practical steps for getting started with your own Git repositories. By the end of this guide, you will have a clear understanding of how Git works and how it can transform the way you develop software.

Before diving into Git, it’s important to understand what version control is.
Version control is a system that records changes to files over time so that you can recall specific versions later. It allows you to:
Without version control, managing code changes manually can be chaotic and error-prone.
Git is a distributed version control system, meaning every developer has a full copy of the repository, including its history. This offers several advantages:
Git is also free, open-source, and widely supported, making it the industry standard for version control.
Here are some essential Git concepts every beginner should know:
Getting started with Git is simple. Here’s how:
brew install gitsudo apt install gitgit config --global user.name "Your Name" git config --global user.email "your.email@example.com"mkdir my-project cd my-project git initgit status This shows which files are tracked, untracked, or staged for commit.git add . git commit -m "Initial commit"Branches are a powerful feature in Git. They let you:
Example:
git branch new-feature # Create a new branch
git checkout new-feature # Switch to the new branch
git commit -m "Add new feature"
git checkout main # Switch back to main
git merge new-feature # Merge changes
Git shines in collaboration. Platforms like GitHub, GitLab, and Bitbucket make it easy to share code.
Common commands:
git clone https://github.com/user/repo.gitgit pull origin maingit push origin maingit diff, git status).
Git is more than just a tool it’s a foundation for modern software development. By learning Git, you gain control over your code, improve collaboration, and reduce the risk of errors. Start small, practice the basics, and gradually explore advanced features like rebasing, stash, and hooks. Once you master Git, you’ll wonder how you ever managed code without it.
Embrace Git, and make your development workflow smoother, safer, and more productive!

In today’s fast-paced software development world, delivering high-quality applications quickly has become more important than ever. Modern development teams are under constant pressure to release new features, fix bugs, and respond to user feedback without compromising quality. Traditional methods of software integration and deployment, where changes were merged infrequently and releases happened sporadically, often led to major bottlenecks, unexpected errors, and frustrated teams.
Developers would spend days or even weeks trying to integrate code from multiple contributors, only to discover conflicts or bugs at the last minute. This approach slowed down innovation and increased the risk of failures in production environments. To overcome these challenges, the concepts of Continuous Integration (CI) and Continuous Delivery/Deployment (CD) emerged.
These practices are now considered essential pillars of modern DevOps culture and agile development. CI and CD are not just technical processes; they represent a shift in mindset towards automation, collaboration, and continuous improvement. By integrating code frequently, automating tests, and delivering software reliably, teams can release updates faster and more confidently.
Continuous Integration focuses on ensuring that developers’ code changes are merged into a shared repository regularly, while Continuous Delivery and Continuous Deployment emphasize making that code ready for release and, in some cases, deploying it automatically. Implementing CI/CD pipelines helps organizations reduce integration issues, catch bugs earlier, and minimize manual intervention in the deployment process.
The result is faster time-to-market, higher software quality, and improved team productivity. Furthermore, CI/CD practices encourage developers to write smaller, incremental changes rather than large, risky updates, making it easier to track issues and maintain code quality. In addition, automated testing within CI/CD pipelines ensures that only code that passes rigorous validation reaches production or staging environments. Beyond testing, CI/CD pipelines often include steps for code linting, security checks, and compliance verification, providing a holistic approach to software reliability.
Organizations that embrace CI/CD can respond more quickly to user feedback, deploy new features incrementally, and maintain a competitive edge in an increasingly digital world. While CI/CD can seem complex at first, the principles behind them are straightforward: integrate often, test thoroughly, and deliver continuously. By understanding the difference between CI and CD and how they complement each other, teams can design pipelines that not only automate tedious tasks but also promote collaboration, accountability, and faster delivery cycles.
In essence, CI/CD is about building a culture where software is always in a deployable state, and developers can innovate without fear of breaking existing functionality. This approach transforms the development workflow from a series of isolated, error-prone steps into a smooth, automated process where quality and speed coexist.
As software development continues to evolve, CI/CD remains a foundational practice for organizations striving for agility, reliability, and excellence. In this blog, we will delve deeper into the differences between Continuous Integration and Continuous Delivery/Deployment, explore how they work, and discuss why adopting these practices is crucial for modern development teams seeking efficiency, consistency, and competitive advantage.

Continuous Integration (CI) is the practice of merging code changes from multiple developers into a shared repository frequently often multiple times a day.
The main goals of CI are:
Benefits of CI:
Example Tools: Jenkins, GitHub Actions, GitLab CI, CircleCI
CD can actually mean two slightly different things, which is why it’s easy to get confused:
Continuous Delivery ensures that code changes are automatically prepared for a release to production. While deployment is manual, the pipeline is fully automated up to that point.
Key Points:
Continuous Deployment takes it a step further every change that passes automated tests is automatically deployed to production.
Key Points:
Example Tools: Spinnaker, ArgoCD, AWS CodePipeline
| Aspect | Continuous Integration (CI) | Continuous Delivery (CD) | Continuous Deployment (CD) |
|---|---|---|---|
| Goal | Integrate code frequently | Prepare code for release | Deploy code automatically |
| Deployment | No | Manual trigger | Automatic |
| Frequency | Multiple times a day | Often, but manual | Often, automatic |
| Automation | Build & Test | Build, Test, Package | Build, Test, Package, Deploy |
In short: CI is about integrating code safely, while CD is about delivering or deploying that code safely.

CI and CD are two pillars of modern software development that work hand-in-hand. CI focuses on integrating code safely and frequently, while CD focuses on delivering or deploying it safely and efficiently. Together, they help teams release high-quality software faster, with fewer headaches.
Embracing CI/CD isn’t just about automation it’s about creating a culture of continuous improvement and collaboration.

Ansible has emerged as one of the most popular tools for automating IT infrastructure.
It allows system administrators and DevOps engineers to manage servers, deploy applications, and orchestrate complex workflows efficiently. One of the key strengths of Ansible is its simplicity; you don’t need agents installed on remote machines, just SSH access. At the core of Ansible’s automation lies the concept of inventory files, which define the hosts that Ansible will manage.
An inventory file is essentially a structured list of all your servers, grouped logically according to their role or environment. Whether you have a handful of servers or thousands across multiple cloud providers, an inventory provides a single source of truth for automation. Without a properly defined inventory, your playbooks wouldn’t know which hosts to target or how to configure them. Think of it as a roadmap that guides Ansible to every machine that needs attention. The inventory also allows you to organize hosts into groups such as web servers, databases, or application servers.
By grouping hosts, you can apply tasks selectively, reducing redundancy and ensuring consistent configuration. Variables can also be assigned at the host or group level, providing a flexible mechanism for customization. This enables different servers to run the same playbook but with unique settings, such as ports, usernames, or package versions. Ansible supports two main types of inventories: static and dynamic.
Static inventories are manually defined, typically in INI or YAML format, and are perfect for small-scale or predictable environments. Dynamic inventories, on the other hand, fetch host data from external sources such as cloud providers, making them ideal for large, elastic infrastructures. The distinction between static and dynamic inventories is essential to understand before diving into more advanced automation.
Moreover, inventory files are not just lists of hosts; they are central to best practices in Ansible management. Organizing your inventory effectively can save time, reduce errors, and make scaling your automation seamless.
Variables stored in the inventory allow you to avoid hardcoding sensitive information directly into playbooks. For instance, credentials, ports, and configuration paths can all be stored in group or host variables. This approach enhances security while maintaining the flexibility of your automation scripts.
In addition, a well-structured inventory makes collaboration easier among team members. When multiple engineers are working on the same infrastructure, a shared inventory file ensures everyone is aligned.
It also allows for better version control when stored in systems like Git, providing history and rollback capabilities.
Another benefit of inventories is that they provide clarity in multi-environment setups.
You can separate staging, testing, and production servers into different groups for safe, controlled deployments. Ansible’s inventory system is not limited to physical servers; it also works with virtual machines, containers, and cloud instances.
This flexibility allows teams to manage hybrid environments with a single automation framework.
Understanding the basics of inventory files is the first step toward mastering Ansible. Before you can write complex playbooks or implement multi-tier deployments, you need to know which hosts you’re targeting.
Many beginners overlook inventories, jumping straight into playbooks, which can lead to confusion and errors. Investing time in learning inventory fundamentals pays off when scaling your automation across dozens or hundreds of hosts.
Moreover, inventory files can evolve over time, accommodating new hosts, roles, or environments without rewriting playbooks. This dynamic nature makes Ansible a practical tool for modern, rapidly changing IT infrastructures. Even simple static inventories provide powerful control when paired with variables and groups. Dynamic inventories extend this power, allowing automation to keep pace with cloud scaling and ephemeral resources. By mastering inventory basics, you set a solid foundation for writing reusable, maintainable, and reliable playbooks. It also prepares you for more advanced topics, such as dynamic group creation, nested groups, and API-driven inventories.
Ultimately, the inventory file is the bridge between your infrastructure and your automation code.
Without it, Ansible has no context; with it, Ansible can orchestrate complex workflows across diverse environments. A deep understanding of inventory files allows engineers to automate confidently and avoid common pitfalls. It also makes troubleshooting easier because you know exactly which hosts are targeted and with which variables. As we move forward, we’ll explore the structure, syntax, and best practices for creating effective Ansible inventories. By the end of this guide, you’ll understand how to create inventories that are scalable, organized, and secure.
Whether you’re just starting with Ansible or looking to improve your current setup, this knowledge is crucial. Let’s begin by exploring the basic concepts of hosts, groups, and variables in an inventory file.
From there, we’ll dive into examples that demonstrate both static and dynamic inventories in real-world scenarios.
With a strong foundation in inventory basics, you’ll be ready to automate your infrastructure efficiently and confidently.

An inventory file is essentially a list of your servers (or hosts) that Ansible can manage. It defines:
An inventory file can be static (manually written) or dynamic (automatically generated).
A static inventory file is a simple text file where you manually define your hosts and groups. There are two main formats:
The INI format is classic and widely used:
[webservers]
web1.example.com
web2.example.com
[databases]
db1.example.com
db2.example.com
[all:vars]
ansible_user=ubuntu
ansible_ssh_private_key_file=~/.ssh/id_rsa
[webservers] and [databases] are groups.[all:vars] defines variables applied to all hosts.YAML is more modern and readable:
all:
vars:
ansible_user: ubuntu
ansible_ssh_private_key_file: ~/.ssh/id_rsa
children:
webservers:
hosts:
web1.example.com:
web2.example.com:
databases:
hosts:
db1.example.com:
db2.example.com:
YAML allows for more complex structures and is preferred for larger inventories.
Variables can be assigned to either hosts or groups:
You can define variables specific to a single host:
web1.example.com ansible_port=2222
Group variables apply to all hosts in a group:
[webservers:vars]
http_port=80
This ensures consistency across similar servers.
While static inventories are great for small environments, dynamic inventories are necessary for cloud or containerized environments.
Dynamic inventories pull host information from APIs, like AWS, Azure, or Kubernetes, keeping your inventory automatically up to date.
Example: Using AWS EC2 inventory plugin:
ansible-inventory -i aws_ec2.yaml --list
This command lists all EC2 instances as Ansible hosts dynamically.
[webservers], [databases], [staging], [production].
Ansible inventory files are the foundation of your automation. By understanding hosts, groups, and variables, you can manage any environment efficiently. Start small with a static inventory, then explore dynamic inventories as your infrastructure grows.

In today’s fast-paced world of IT infrastructure and cloud computing, automation has become an essential skill for system administrators, DevOps engineers, and IT professionals alike. Organizations increasingly rely on automation tools to reduce manual errors, save time, and ensure consistent configuration across hundreds or even thousands of servers.
Among the myriad of automation tools available, Ansible stands out for its simplicity, efficiency, and powerful capabilities. Unlike traditional configuration management tools that often require agents installed on remote servers, Ansible operates agentlessly, using SSH or WinRM to communicate with managed nodes. This approach minimizes overhead, reduces security risks, and simplifies deployment.
Ansible is also declarative in nature, which means that rather than instructing a server how to perform each step, you describe the desired state, and Ansible takes care of achieving that state. This model allows IT teams to focus on defining outcomes rather than micromanaging execution, leading to more reliable and reproducible infrastructure. At its core, Ansible consists of modules, playbooks, and inventories. Modules are pre-written scripts that handle specific tasks such as installing packages, managing users, or deploying applications. Playbooks, written in YAML, are structured sets of instructions that define tasks, their order, and the hosts they apply to. Inventories list the hosts and groups of hosts that Ansible manages, allowing users to target operations precisely.
One of the key strengths of Ansible is its readability and simplicity. Even beginners with limited programming experience can quickly understand YAML syntax and start writing effective playbooks. Additionally, Ansible has a vibrant ecosystem, including Ansible Galaxy, where users can share and download pre-built roles to accelerate automation projects.
Ansible’s flexibility allows it to manage not only Linux servers but also Windows machines, network devices, and cloud infrastructure, making it a versatile tool for modern IT environments. Furthermore, it integrates seamlessly with CI/CD pipelines, enabling automated deployments, configuration drift management, and infrastructure-as-code practices.
The learning curve for Ansible is relatively gentle compared to other tools, making it accessible for beginners while still offering advanced features for seasoned professionals. By mastering basic Ansible commands and gradually exploring more complex playbooks, users can automate repetitive tasks, enhance operational efficiency, and reduce human errors.
Moreover, Ansible promotes collaboration between development and operations teams, aligning with DevOps principles and fostering a culture of shared responsibility for infrastructure management. Security is another area where Ansible shines, as sensitive information such as passwords and API keys can be encrypted and managed securely using Ansible Vault.
For anyone starting their automation journey, learning the most commonly used Ansible commands is crucial. These commands provide the foundation for testing connectivity, running tasks, managing inventories, and deploying playbooks. By understanding these commands, beginners gain confidence in interacting with remote servers, orchestrating complex workflows, and troubleshooting issues effectively.
Over time, this foundational knowledge serves as a stepping stone toward more advanced automation concepts, such as role-based playbooks, dynamic inventories, and integrating Ansible with monitoring and alerting systems. Ultimately, proficiency in Ansible empowers IT professionals to streamline infrastructure management, increase reliability, and contribute meaningfully to organizational efficiency.

ansible --versionBefore anything else, you need to check if Ansible is installed and verify its version.
ansible --version
This command displays the installed Ansible version and configuration details like Python version and the location of Ansible’s configuration file.
ansible all -m pingThis is the first command every beginner should try. It tests the connectivity between your control node and managed nodes.
ansible all -m ping
Here, -m ping uses the ping module (not the system ping) to verify that Ansible can communicate with your hosts.
ansible -i inventory all -m shell -a "uptime"Ansible can run ad-hoc commands on remote servers without writing a playbook.
ansible -i inventory all -m shell -a "uptime"
-i inventory specifies the inventory file.-m shell tells Ansible to use the shell module.-a "command" is the command to execute.This is perfect for quick tasks like checking uptime, disk space, or restarting services.
ansible-galaxy install <role_name>Ansible Galaxy is a hub for sharing roles and collections. To install a role:
ansible-galaxy install geerlingguy.nginx
This command downloads a reusable role that can configure Nginx automatically.
ansible-playbook <playbook.yml>Playbooks are where the magic happens. To run a playbook:
ansible-playbook site.yml
ansible-vault create <file.yml>Security matters! Ansible Vault lets you encrypt sensitive files.
ansible-vault create secrets.yml
You can store passwords, API keys, or any confidential information securely.
ansible-doc <module_name>Ansible has hundreds of modules. To learn how to use a specific module:
ansible-doc yum
This shows the module’s documentation, options, and examples directly in your terminal.
ansible-inventory --list -i inventoryManaging hosts can be tricky. To see all hosts in your inventory:
ansible-inventory --list -i inventory
This prints all groups and hosts in JSON format and helps ensure your inventory is configured correctly.
ansible-playbook <playbook.yml> --checkWant to see what changes would happen without actually applying them? Use check mode:
ansible-playbook site.yml --check
This “dry run” mode is essential for testing playbooks safely.
ansible-playbook <playbook.yml> --diffWhen you need to see what changes Ansible would make to files:
ansible-playbook site.yml --diff
This is especially useful for configuration management, as it shows exactly what lines are added or removed.
-v for verbose output: ansible-playbook site.yml -v This helps debug issues when tasks fail.--check and --diff together to see potential changes safely.
Mastering these 10 essential Ansible commands will give you a solid foundation in automation. From testing connectivity to running playbooks, managing inventory, and securing sensitive data, these commands cover the basics every beginner needs. As you grow more comfortable, exploring Ansible modules and advanced playbooks will become much easier.

In today’s rapidly evolving digital landscape, organizations of all sizes face unprecedented pressure to deliver software quickly, reliably, and efficiently, often in environments that are more complex and dynamic than ever before. The traditional models of IT operations, which served businesses effectively for decades, are increasingly struggling to keep up with the pace of innovation, the demand for continuous service availability, and the need for faster delivery of features and updates.
Historically, IT operations have relied on a structured, siloed approach in which development teams write code, quality assurance tests it, and operations teams deploy and maintain the systems in production. While this approach has the advantage of clear responsibility boundaries and stability in predictable environments, it often results in long release cycles, delayed feedback, and bottlenecks between teams. Every handoff introduces the potential for miscommunication, error, and inefficiency, and as the complexity of software and infrastructure grows, these challenges are magnified.
Enter DevOps a cultural and technical movement designed to address these very limitations by fostering collaboration, shared responsibility, and continuous improvement across the software lifecycle. DevOps is not merely a set of tools or technologies; it represents a fundamental shift in how organizations approach software development and operations, breaking down traditional silos and creating integrated, agile workflows that allow teams to respond rapidly to changing business needs.
By emphasizing automation, continuous integration, continuous delivery, monitoring, and feedback loops, DevOps aims to increase speed, reliability, and quality while reducing operational risk. This transformation is driven not just by technological advances but also by evolving customer expectations, competitive pressures, and the realization that traditional operational methods cannot sustain the speed and scale required in modern digital ecosystems.
From startups to enterprises, organizations that fail to adapt risk slower time-to-market, higher failure rates, and decreased customer satisfaction, whereas those embracing DevOps can innovate faster, recover from failures more quickly, and maintain a resilient infrastructure capable of supporting continuous growth.
The contrast between traditional IT operations and DevOps highlights a broader shift in the industry toward agility, collaboration, and automation, raising important questions about team structure, workflow design, risk management, and performance measurement. Understanding these differences is critical for leaders, managers, and technical professionals who seek to improve operational efficiency, deliver business value, and stay competitive in an environment where technology is a key differentiator.
In this article, we will explore the distinctions between traditional IT operations and DevOps, examine the benefits and challenges of adopting DevOps practices, and provide insights into why this cultural and technological shift has become essential for modern organizations seeking to balance speed, stability, and innovation in software delivery. By the end, readers will gain a comprehensive understanding of how DevOps transforms software delivery, improves collaboration, reduces risk, and enhances the overall performance of IT teams.

Traditional IT operations (often called “ITIL-style operations”) follows a siloed, structured approach. Typically, the development team writes the code, then hands it over to operations to deploy and manage. The workflow often looks like this:
Key characteristics of traditional IT operations include:
While this model is reliable for stable, low-change environments, it struggles to keep up with today’s demand for rapid innovation.
DevOps is a cultural and technical movement that integrates development (Dev) and operations (Ops) into a single, collaborative process. Its goal is to automate and streamline software delivery while maintaining reliability and security.
Key characteristics of DevOps include:
DevOps isn’t just about tools it’s a cultural shift that emphasizes communication, shared responsibility, and continuous improvement.
| Aspect | Traditional IT Operations | DevOps |
|---|---|---|
| Team Structure | Siloed (Dev, Ops, QA separate) | Cross-functional, collaborative teams |
| Workflow | Sequential (waterfall) | Iterative and continuous (CI/CD) |
| Release Frequency | Weeks or months | Days or hours |
| Automation | Limited, manual processes | Extensive automation of testing, deployment, and monitoring |
| Risk Management | Testing late in the cycle, higher chance of failure | Continuous testing and monitoring, faster issue resolution |
| Feedback Loop | Slow, post-deployment | Continuous, real-time feedback |
| Culture | Responsibility divided | Shared responsibility and accountability |

While traditional IT operations have served businesses for decades, they are often too slow and rigid for today’s digital demands. DevOps offers a modern approach that combines culture, process, and automation to deliver software faster, safer, and more efficiently. For organizations looking to innovate quickly, reduce risk, and improve collaboration, DevOps isn’t just an option it’s becoming the standard.
Pro Tip: If you’re starting your DevOps journey, begin with small, incremental automation and cross-team collaboration. Even small changes can lead to big efficiency gains.

In today’s rapidly evolving IT world, automation has shifted from being a luxury to becoming an absolute necessity, as modern infrastructure grows more complex and challenging to manage manually, pushing teams to adopt smarter, more reliable ways to maintain consistency, reduce errors, and improve operational speed across their environments, which is why tools like Ansible have become so widely embraced by developers, system administrators, and DevOps engineers who need scalable automation,
because Ansible simplifies configuration management through its agentless design, allowing users to automate tasks using clear and human-readable instructions, written in YAML so that even beginners can understand the workflow easily, and at the core of this automation framework lies the Ansible playbook,
a structured file that defines what actions should be executed on systems, serving as a blueprint that guides Ansible step by step through each process, ensuring that systems are configured exactly the same way every single time, removing the inconsistencies that often come from manual configuration work,
and giving teams the confidence to scale operations without fear of mistakes, because with playbooks, tasks like installing packages or managing services can be executed across dozens or thousands of servers with a single command, turning time-consuming administrative tasks into seamless automated workflows,
and enabling organizations to focus more on innovation instead of repetitive work, since playbooks bring clarity, repeatability, and speed to infrastructure tasks, making them an essential part of modern automation strategies everywhere, especially for beginners who want to build a strong foundation in Ansible, because understanding playbooks unlocks the true power of the platform, helping new users grasp how automation is structured and executed effectively, while giving them a practical starting point for real-world DevOps practices, and as you explore Ansible further, the importance of playbooks becomes clear, showing how they transform complex tasks into simple, organized procedures, ultimately demonstrating why playbooks are considered the heart of Ansible, and why mastering them is the first step toward mastering automation itself.

An Ansible playbook is a YAML file that defines tasks, configurations, and automated workflows for one or more systems.
When you run a playbook, Ansible reads the file and executes each task in order ensuring your servers end up exactly the way you want them.
Think of a playbook as a recipe:
You list the ingredients (hosts, variables)
You give step-by-step instructions (tasks)
Ansible follows the recipe to produce consistent results every time
Why Are Playbooks So Useful?
✔ 1. They’re Easy to Read and Write
Playbooks use YAML, which is human-friendly and doesn’t require complex programming skills.
✔ 2. They’re Repeatable and Reliable
Run the same playbook 10 or 1,000 times it produces the same outcome.
✔ 3. They Reduce Human Error
No more forgetting to install a package or configure a file correctly.
✔ 4. They Save Massive Amounts of Time
A single command can configure dozens of servers.
What Does a Simple Playbook Look Like?
Here’s a minimal example of an Ansible playbook that installs NGINX:
name: Install NGINX on web servers
hosts: webservers
become: yes tasks:name: Install nginx package
apt:
name: nginx
state: presentname: Ensure nginx is running
service:
name: nginx
state: started
enabled: true
Even beginners can understand what’s happening by reading the YAML.
A play maps a group of hosts to a set of tasks.
“Run these tasks on these servers.”
Individual automated steps, such as installing a package or writing a file.
The “tools” Ansible uses for example:
apt (install packages)
service (manage services)
copy (transfer files)
Let you reuse values and keep playbooks flexible.
Special tasks triggered by changes great for restarting services only when needed.
Assuming your playbook is named site.yml, run:
ansible-playbook site.ymlAnsible connects to your servers over SSH and executes everything automatically.
In real-world DevOps workflows, playbooks are used for:
Because they’re declarative and idempotent, playbooks ensure infrastructure stays predictable even in complex environments.

Ansible playbooks are the heart of automation in Ansible. They allow you to manage systems consistently, efficiently, and securely using simple YAML files. Whether you’re configuring a single server or orchestrating an entire infrastructure, playbooks are your blueprint for automation success.
If you’re just starting out with Ansible, learning how to write and use playbooks opens the door to powerful DevOps workflows and dramatically reduces the time you spend on repetitive work.

In the world of IT operations and system administration, automation has become a critical factor for efficiency and reliability. Organizations are constantly seeking ways to reduce repetitive manual tasks and minimize human error in their processes. Automation allows teams to maintain consistency across environments and streamline deployment workflows. Two popular approaches for system automation are Bash scripts and Ansible. Bash scripts have been a long-standing tool for administrators, offering direct command-line control over systems.
They are procedural, meaning each step must be explicitly defined by the user. Bash scripts are highly flexible and allow deep interaction with the underlying operating system. Complex logic can be implemented using loops, conditionals, and functions within Bash. However, as scripts grow larger, they can become harder to maintain and debug. Error handling in Bash typically relies on manual checks and careful scripting. On the other hand, Ansible represents a modern approach to automation using a declarative model. With Ansible, users describe the desired state of systems rather than the individual commands.
Ansible playbooks are written in YAML, making them readable and structured. The tool ensures idempotency, so repeated runs do not change systems unnecessarily. Ansible can manage multiple servers simultaneously with built-in parallel execution. It abstracts many low-level operations, allowing teams to focus on outcomes rather than step-by-step commands.
Error reporting and logging in Ansible are more structured than in Bash, simplifying troubleshooting.
Ansible also promotes modular design, encouraging reusable roles and playbooks. While Bash scripts are ubiquitous and widely known by Unix/Linux users, Ansible requires learning its modules and syntax.
Security considerations differ between the two approaches, with Ansible promoting safer practices by default.
Bash scripts can inadvertently expose sensitive data if not carefully written. The choice between Bash and Ansible often depends on the scale and complexity of the task. Small, ad-hoc operations or single-system automation may favor Bash due to its simplicity. For larger deployments, multi-server orchestration, or configuration management, Ansible is usually more efficient.
Hybrid approaches are also common, where Bash scripts are called within Ansible playbooks. Understanding the strengths and limitations of both tools is essential for effective automation planning. Ansible reduces manual overhead and enforces consistency across environments. Bash offers granular control and flexibility for custom or one-off tasks.
Ansible’s declarative approach reduces the likelihood of errors in complex workflows. Bash’s procedural nature requires meticulous scripting but allows precise execution. Maintenance and scalability are important considerations when choosing between the two. Ansible’s modular structure makes it easier to update and extend automation workflows. Bash scripts may require additional effort to maintain as they grow in size.
Integration with other tools and cloud environments is generally smoother with Ansible. Bash can integrate with other tools, but it often requires more manual effort. Team collaboration is typically more efficient with Ansible due to its readable playbooks. Bash scripts may require detailed documentation for team use. Idempotency and repeatable automation are major advantages of Ansible in production environments. Bash may be sufficient for local or simple tasks but can become risky in larger deployments.
The learning curve for Ansible is offset by long-term benefits in automation efficiency. Bash’s familiarity makes it a quick solution for experienced administrators. Ultimately, the decision comes down to task requirements, scale, and team expertise. Recognizing when to use Bash versus Ansible can save time, reduce errors, and improve reliability.
Combining both tools strategically can maximize efficiency and flexibility. Modern IT teams often adopt Ansible for core automation while using Bash for specialized tasks. By evaluating the needs of your infrastructure, you can choose the right tool for the right job.
Automation is not just about convenience; it is a strategic advantage in today’s technology landscape.
This guide explores the key differences between Ansible and Bash scripts and helps determine when each is most appropriate.

Bash (Bourne Again Shell) is a command-line shell and scripting language used on most UNIX-based systems. If you’ve ever typed commands like ls, cd, or sudo apt install, you’ve used Bash.
Bash scripts are:
But Bash is also imperative meaning it tells the system how to perform actions step by step.
Ansible is an automation tool designed for configuration management, provisioning, orchestration, and application deployment.
Key characteristics:
Ansible is declarative meaning you define what the desired state should be, and Ansible figures out how to get there.
| Feature | Ansible | Bash |
|---|---|---|
| Type | Declarative / configuration management | Imperative / command-by-command |
| Scaling | Excellent—designed for many hosts | Poor—manual loops + SSH needed |
| Idempotency | Built-in | Requires custom logic |
| Readability | High (YAML) | Medium to low for complex scripts |
| Error handling | Structured and consistent | Manual and error-prone |
| Dependencies | Requires control node + Python | Runs natively on most Linux systems |
| Best for | Multi-host automation, state consistency | Quick tasks, one-off scripts |
#!/bin/bash
tar -czf backup.tar.gz /var/www/html
echo "Backup completed!"
Bash excels at small tasks like this fast, minimal overhead, and easy to run.
- name: Setup web server
hosts: webservers
become: yes
tasks:
- name: Install nginx
package:
name: nginx
state: present
- name: Start nginx
service:
name: nginx
state: started
enabled: true
In Ansible, the above tasks will run cleanly and repeatedly across any number of hosts.
If you ever find yourself writing a Bash script with multiple SSH loops or conditional states, you’re probably doing something Ansible could handle better.
Running a Bash script twice might:
Ansible avoids this by default. For example, the package module won’t reinstall something that’s already installed.

Bash and Ansible are both powerful tools, but they serve different purposes. Bash is best for small, local, quick, and procedural tasks, while Ansible excels at scalable, consistent, and idempotent automation across many systems. In modern DevOps environments, the two often complement each other rather than compete Bash handles simple logic, while Ansible manages large-scale deployments and system configurations. Understanding when to use each tool empowers you to build cleaner automation, reduce errors, and manage systems more effectively.

Ansible has quickly become one of the most popular automation tools in the DevOps and IT world, thanks to its simplicity, readability, and ability to automate nearly anything without requiring agents on the machines it manages. For absolute beginners, the most important first step is understanding how Ansible thinks and how its core components playbooks, modules, and inventories work together to turn complex tasks into predictable, repeatable workflows.
While many automation tools demand steep learning curves or complicated setups, Ansible focuses on clarity and ease of use, allowing new users to start automating real systems with only a handful of concepts. You don’t need to be an expert in scripting or configuration management to get started; you only need to grasp how Ansible organizes machines, how it executes actions, and how it expresses desired system states through simple YAML files.
Inventories help Ansible understand which hosts to connect to, modules define what actions should be performed, and playbooks combine those actions into structured, logical automation steps. Once you understand these three elements, the rest of Ansible becomes far more intuitive, and you gain the confidence to automate tasks that were previously repetitive or error-prone. This introduction will guide you through these fundamentals in a clear and beginner-friendly way, showing how each concept fits into the bigger automation picture and preparing you to build your first real playbooks with ease.

Ansible is an open-source tool that automates tasks such as installing packages, configuring services, setting up applications, deploying code, and managing entire infrastructures. Its biggest strengths are:
Before running anything in Ansible, you need to understand the three core building blocks below.
The inventory is simply a list of hosts (servers, containers, network devices) that Ansible will connect to.
[webservers]
192.168.1.10
192.168.1.11
[dbservers]
db.example.com
Inventories are the foundation before you automate anything, you must tell Ansible where to act.
Ansible modules are small units of work like commands Ansible runs on target machines.
You rarely write modules yourself; you use them.
ping – test connectivitypackage / yum / apt – manage packagesuser – create or modify system usersservice – start, stop, enable servicescopy – copy filestemplate – generate files from Jinja2 templatesgit – clone repositoriesansible all -m ping -i hosts.ini
This command checks whether Ansible can reach all servers in the inventory.
- name: Install Apache
ansible.builtin.package:
name: httpd
state: present
Modules are the “verbs” of Ansible they do the actual work.
If modules are verbs, playbooks are the sentences.
A playbook brings tasks together in a sequence that describes the desired state of your system.
Playbooks are written in YAML and define:
- name: Configure web server
hosts: webservers
become: yes
tasks:
- name: Install Apache
ansible.builtin.package:
name: httpd
state: present
- name: Start Apache
ansible.builtin.service:
name: httpd
state: started
enabled: true
Run it with:
ansible-playbook -i hosts.ini site.yml
The playbook tells Ansible what to do, where to do it, and in what order.
Think of Ansible automation like a sentence:
When you run a playbook, Ansible:
This simple model scales from a single VM to thousands of servers.
Here’s a beginner-friendly playbook that installs NGINX and deploys an index page:
- name: Setup NGINX web server
hosts: webservers
become: yes
tasks:
- name: Install nginx
ansible.builtin.package:
name: nginx
state: present
- name: Ensure nginx is running
ansible.builtin.service:
name: nginx
state: started
enabled: true
- name: Add default index page
ansible.builtin.copy:
content: "Welcome to Ansible!"
dest: /usr/share/nginx/html/index.html
One playbook, three tasks and a fully automated web server.

Ansible is powerful, but its strength lies in its simplicity. Once you understand inventories, modules, and playbooks, you’ve already mastered the core concepts needed to automate real infrastructure. Everything else roles, variables, handlers, collections, and CI pipelines builds on these foundations. With just a few YAML files and a basic inventory, you can automate the repetitive tasks that consume your time, reduce errors, and bring consistency to your environment. Now that you’ve grasped the essentials, you’re ready to take the next steps and build more sophisticated automation with confidence.

In the modern era of software development and deployment, technology continues to evolve at an astonishing pace, introducing new paradigms that change how developers, DevOps engineers, and IT teams build, ship, and manage applications. One of the most transformative concepts in this evolution is virtualization, which allows multiple isolated computing environments to coexist on the same physical hardware.
Over the years, two primary approaches to virtualization have emerged as dominant in the industry: virtual machines (VMs) and containers. Virtual machines, which have been around for decades, provide a way to emulate entire computers, including their own operating systems, on a shared hardware platform. They offer strong isolation, robust security, and the ability to run multiple operating systems on the same host, making them indispensable for legacy applications and enterprise workloads.
Containers, on the other hand, are a more recent innovation that leverage operating system–level virtualization to provide lightweight, portable, and fast environments for applications. By sharing the host operating system kernel, containers eliminate the overhead of running a full guest OS for every application, allowing developers to deploy and scale applications rapidly.
Despite sharing the common goal of isolating workloads, VMs and containers differ significantly in architecture, performance, resource utilization, scalability, and operational complexity. For many organizations, understanding these differences is crucial for making informed decisions about infrastructure, development workflows, and deployment strategies. In 2025, containers have become the go-to technology for modern cloud-native applications, microservices architectures, and CI/CD pipelines, while VMs continue to provide essential capabilities for legacy systems, high-security environments, and multi-OS requirements.
However, the decision between containers and VMs is rarely binary. Many enterprises employ a hybrid approach, combining the strengths of both technologies to optimize efficiency, scalability, and operational flexibility. For instance, containers are often deployed inside VMs to achieve both lightweight scalability and strong isolation, providing a balance between modern application demands and enterprise-grade security.
Additionally, cloud providers like AWS, Azure, and Google Cloud offer integrated solutions that blend containerization and virtualization, giving teams unprecedented flexibility in how they run workloads. Despite the growing popularity of containers, the maturity, stability, and ecosystem support of VMs remain highly relevant for certain use cases.
Developers need to consider multiple factors when deciding which technology to use, including application architecture, resource constraints, security requirements, operational complexity, team expertise, and long-term maintainability. Containers excel in scenarios where rapid deployment, portability, and horizontal scaling are critical, such as microservices-based applications and automated CI/CD pipelines.
Virtual machines, in contrast, shine when complete isolation, support for multiple operating systems, or compliance-driven security controls are paramount. Moreover, understanding the trade-offs between containers and VMs is not only a technical concern but also a strategic business decision, as the choice directly impacts infrastructure costs, team productivity, deployment speed, and application reliability. For beginners and experienced engineers alike, mastering the nuances of both technologies is essential for designing resilient, scalable, and efficient systems.
This blog explores the architecture, benefits, drawbacks, and ideal use cases of containers and virtual machines in depth, providing practical guidance for teams deciding which technology or combination of technologies best fits their workloads. By examining performance, resource efficiency, security, scalability, and operational considerations, readers will gain a comprehensive understanding of how to leverage each technology effectively. Ultimately, the choice between containers and virtual machines is context-dependent, and knowing the strengths and limitations of each empowers engineers to make informed, future-proof decisions that align with their application requirements, team capabilities, and business objectives.

Virtual machines are software emulations of physical computers. A hypervisor (like VMware ESXi, Hyper-V, or KVM) allows multiple VMs to run on a single host, each with its own guest operating system, virtual CPU, memory, and storage.
Containers are lightweight, OS-level virtualization that allow applications to run in isolated user spaces while sharing the host OS kernel. Tools like Docker, Podman, and container runtimes (containerd, CRI-O) manage this isolation.
| Feature | Virtual Machines | Containers |
|---|---|---|
| OS | Each VM has its own OS | Share host OS kernel |
| Isolation | Strong, hardware-level | Process-level, weaker |
| Resource Usage | Heavy (full OS per VM) | Lightweight |
| Startup Time | Minutes | Seconds |
| Portability | Moderate | High (same container runs anywhere) |
| Use Case | Legacy apps, multi-OS needs | Microservices, cloud-native apps |
Many organizations use a combination of VMs and containers:

Containers and virtual machines are not competitors they are complementary technologies.
Choosing the right tool depends on your application requirements, team expertise, and operational needs. In 2025, most modern DevOps pipelines favor containers for new development, but VMs remain indispensable for many production workloads. Understanding the trade-offs ensures your infrastructure is efficient, secure, and future-ready.

Docker has long been the foundation of containerized application development, giving developers a simple and consistent way to package, run, and ship software across environments. But as applications evolve beyond a handful of containers, teams inevitably face a critical architectural question: How should we manage and orchestrate these services? For years, two straightforward options within the Docker ecosystem have dominated early-stage projects Docker Compose, the lightweight tool ideal for defining and running multi-container applications on a single machine, and Docker Swarm, Docker’s built-in clustering and orchestration engine designed to scale those applications across multiple hosts. In 2026, however, the container landscape looks different: Kubernetes has become the undisputed industry standard for large-scale orchestration, automation, and infrastructure management, while Docker Swarm’s development pace has slowed and Docker Compose has found its niche primarily in development workflows.
This shift leaves many teams, freelancers, and DevOps engineers wondering which Docker tool still makes sense today. Should you stick with the simplicity of Docker Compose for local development? Can Docker Swarm still serve as a practical, lightweight orchestrator for small production environments? Or does the prevalence of Kubernetes make both options feel outdated? In this blog, we break down the roles, strengths, limitations, and modern relevance of Docker Compose and Docker Swarm, giving you the clarity you need to decide which tool if any is the right fit for your workflow in 2026.

Docker Compose is a simple tool for defining and running multi-container applications using a declarative YAML file (docker-compose.yml). It’s primarily used for:
Compose is fantastic for developers but not for distributed systems.
Docker Swarm Mode adds orchestration capabilities to Docker, enabling:
docker service scale)While Swarm still works, it is no longer a strategic priority in Docker’s roadmap.
| Feature | Docker Compose | Docker Swarm |
|---|---|---|
| Primary Use Case | Local dev | Lightweight orchestration |
| Scalability | Single host | Multi-node cluster |
| Service Discovery | Basic | Built-in |
| Load Balancing | No | Yes |
| High Availability | No | Yes (manager replicas) |
| Learning Curve | Very easy | Easy |
| Production Suitability | Limited | Small-to-medium deployments |
| Ecosystem Support (2026) | Strong | Declining |
By 2025, Kubernetes is the default choice for:
Even Docker’s official stance positions Kubernetes (not Swarm) as the long-term orchestration target.
But Kubernetes comes with operational overhead, which means small teams may still prefer Swarm.
Choose Compose if you need:
✓ Local development environments
✓ Simple, small applications
✓ Quick prototyping
✓ One-off deployments on a single VM
✓ Lightweight CI environments
If your environment does not require high availability or distribution, Compose is perfect.
Use Swarm if you want:
✓ A simpler alternative to Kubernetes
✓ Small production clusters
✓ An orchestration layer that uses the Docker CLI directly
✓ Built-in secrets, service discovery, and load balancing
✓ A cluster that’s fast and easy to set up (minutes instead of hours)
Swarm is still fully functional in 2026, but long-term ecosystem support is a concern.
Here’s the practical recommendation for most teams:
Docker Compose is the best choice.
Docker Swarm is acceptable, but be aware of slower community momentum.
Use Kubernetes, or a managed service like EKS, GKE, or AKS.

Docker Compose and Docker Swarm still serve useful (but different) roles in 2026.
Your choice depends on your team size, complexity, resilience needs, and long-term scalability goals.
